
TypeScript: The Missing Introduction
The purpose of this article is to offer an introduction to how we can think about TypeScript, and its role in supercharging our JavaScript development.
We will also try and come up with our own reasonable definitions for a lot of the buzzwords surrounding types and compilation.
There is huge amount of great stuff in the TypeScript project that we won’t be able to cover within the scope of this blog post. Please read the official documentation to learn more.
Background
TypeScript is an amazingly powerful tool, and really quite easy to get started with.
It can, however, come across as more complex than it is, because it may simultaneously be introducing us to a whole host of technical concepts related to our JavaScript programs that we may not have considered before.
Whenever we stray into the area of talking about types, compilers, etc. things can get really confusing, really fast.
This article is designed as a “what you need to know” guide for a lot of these potentially confusing concepts, so that by the time you dive into the “Getting Started” style tutorials, you are feeling confident with the various themes and terminology that surround the topic.
Getting to grips with the buzzwords
There is something about running our code in a web browser that makes us feel differently about how it works. “It’s not compiled, right?”, “Well, I definitely know there aren’t any types…”
Things get even more interesting when we consider that both of those statements are both correct and incorrect at the same time - depending on the context and how you define some of these concepts.
As a first step, we are going to do exactly that!
JavaScript - interpreted or compiled?
Traditionally, developers will often think about a language being a “compiled language” when they are the ones responsible for compiling their own programs.
In basic terms, when we compile a program we are converting it from the form we wrote it in, to the form it actually gets run in.
In a language like Golang, for example, you have a command line tool called go build which allows you to compile your .go file into a lower-level representation of the code, which can then be executed and run:
# We manually compile our .go file into something we can run
# using the command line tool "go build"
go build awesome-program.go
# ...then we execute it!
./awesome-program
As authors of JavaScript (ignoring our love of new-fangled build tools and module loaders for a moment), we don’t have such a fundamental compilation step in our workflow.
We write some code, and load it up in a browser using a <script> tag (or a server-side environment such as node.js), and it just runs.
Ok, so JavaScript isn’t compiled - it must be an interpreted language, right?
Well, actually, all we have determined so far is that JavaScript is not something that we compile ourselves, but we’ll come back to this after we briefly look an example of an “interpreted language”.
An interpreted computer program is one that is executed like a human reads a book, starting at the top and working down line-by-line.
The classic example of interpreted programs that we are already familiar with are bash scripts. The bash interpreter in our terminal reads our commands in line-by-line and executes them.
Now, if we return to thinking about JavaScript and whether or not it is interpreted or compiled, intuitively there are some things about it that just don’t add up when we think about reading and executing a program line-by-line (our simple definition of “interpreted”).
Take this code as an example:
hello();
function hello() {
console.log('Hello!');
}This is perfectly valid JavaScript which will print the word “Hello!”, but we have used the hello() function before we have even defined it! A simple line-by-line execution of this program would just not be possible, because hello() on line 1 does not have any meaning until we reach its declaration on line 2.
The reason that this, and many other concepts like it, is possible in JavaScript is because our code is actually compiled by the so called “JavaScript engine”, or environment, before it is executed. The exact nature of this compilation process will depend on the specific implementation (e.g. V8, which powers node.js and Google Chrome, will behave slightly differently to SpiderMonkey, which is used by FireFox).
We will not dig any further into the subtleties of defining “compiled vs interpreted” here (there are a LOT).
It’s useful to always keep in mind that the JavaScript code we write is already not the actual code that will be executed by our users, even when we simply have a
<script>tag in an HTML document.
Run Time vs Compile Time
Now that we have properly introduced the idea that compiling a program and running a program are two distinct phases, the terms “Run Time” and “Compile Time” become a little easier to reason about.
When something happens at Compile Time, it is happening during the conversion of our code from what we wrote in our editor/IDE to some other form.
When something happens at Run Time, it is happening during the actual execution of our program. For example, our hello() function above is executed at “run time”.
The TypeScript Compiler
Now that we understand these key phases in the lifecycle of a program, we can introduce the TypeScript compiler.
The TypeScript compiler is at the core of how TypeScript is able to help us when we write our code. Instead of just including our JavaScript in a <script> tag, for example, we will first pass it through the TypeScript compiler so that it can give us helpful hints on how we can improve our program before it runs.
We can think about this new step as our own personal “compile time”, which will help us ensure that our program is written in the way we intended, before it even reaches the main JavaScript engine.
It is a similar process to the one shown in the Golang example above, except that the TypeScript compiler just provides hints based on how we have written our program, and doesn’t turn it into a lower-level executable - it produces pure JavaScript.
# One option for passing our source .ts file through the TypeScript
# compiler is to use the command line tool "tsc"
tsc awesome-program.ts
# ...this will produce a .js file of the same name
# i.e. awesome-program.jsThere are many great posts about the different options for integrating the TypeScript compiler into your existing workflow, including the official documentation. It is beyond the scope of this article to go into those options here.
Dynamic vs Static Typing
Just like with “compiled vs interpreted” programs, the existing material on “dynamic vs static typing” can be incredibly confusing.
Let’s start by taking a step back and refreshing our memory on how much we already understand about types from our existing JavaScript code.
We have the following program:
var name = 'James';
var sum = 1 + 2;How would we describe this code to somebody?
“We have declared a variable called name, which is assigned the string of ‘James’, and we have declared the variable sum, which is assigned the value we get when we add the number 1 to the number 2.”
Even in such a simple program, we have already highlighted two of JavaScript’s fundamental types: String and Number.
As with our introduction to compilation above, we are not going to get bogged down in the academic subtleties of types in programming languages - the key thing is understanding what it means for our JavaScript so that we can then extend it to properly understanding TypeScript.
We know from our traditional nightly ritual of reading the latest ECMAScript specification (LOL, JK - “wat’s an ECMA?”), that it makes numerous references to types and their usage in JavaScript.
Taken directly from the official spec:
An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the ECMAScript language.
The ECMAScript language types are Undefined, Null, Boolean, String, Symbol, Number, and Object.
We can see that the JavaScript language officially has 7 types, of which we have likely used 6 in just about every real-world program we have ever written (Symbol was first introduced in ES2015, a.k.a. ES6).
Now, let’s think a bit more deeply about our “name and sum” JavaScript program above.
We could take our name variable which is currently assigned the string ‘James’, and reassign it to the current value of our second variable sum, which is the number 3.
var name = 'James';
var sum = 1 + 2;
name = sum;The name variable started out “holding” a string, but now it holds a number. This highlights a fundamental quality of variables and types in JavaScript:
The value ‘James’ is always one type - a string - but the name variable can be assigned any value, and therefore any type. The exact same is true in the case of the sum assignment: the value 1 is always a number type, but the sum variable could be assigned any possible value.
In JavaScript, it is values, not variables, which have types. Variables can hold any value, and therefore any type, at any time.
For our purposes, this also just so happens to be the very definition of a “dynamically typed language”!
By contrast, we can think of a “statically typed language” as being one in which we can (and very likely have to) associate type information with a particular variable:
var name: string = 'James';In this code, we are better able to explicitly declare our intentions for the name variable - we want it to always be used as a string.
And guess what? We have just seen our first bit of TypeScript in action!
When we reflect on our own code (no programming pun intended), we can likely conclude that even when we are working with dynamic languages like JavaScript, in almost all cases we should have pretty clear intentions for the usage of our variables and function parameters when we first define them. If those variables and parameters are reassigned to hold values of different types to ones we first assigned them to, it is possible that something is not working out as we planned.
One great power that the static type annotations from TypeScript give us, as JavaScript authors, is the ability to clearly express our intentions for our variables.
This improved clarity benefits not only the TypeScript compiler, but also our colleagues and future selves when they come to read and understand our code. Code is read far more than it is written.
TypeScript’s role in our JavaScript workflow
We have started to see why it is often said that TypeScript is just JavaScript + Static Types. Our so-called “type annotation” : string for our name variable is used by TypeScript at compile time (in other words, when we pass our code through the TypeScript compiler) to make sure that the rest of the code is true to our original intention.
Let’s take a look at our program again, and add another explicit annotation, this time for our sum variable:
var name: string = 'James';
var sum: number = 1 + 2;
name = sum;If we let TypeScript take a look at this code for us, we will now get an error Type 'number' is not assignable to type 'string' for our name = sum assignment, and we are appropriately warned against shipping potentially problematic code to be executed by our users.
Importantly, we can choose to ignore errors from the TypeScript compiler if we want to, because it is just a tool which gives us feedback on our JavaScript code before we ship it to our users.
The final JavaScript code that the TypeScript compiler will output for us will look exactly the same as our original source above:
var name = 'James';
var sum = 1 + 2;
name = sum;The type annotations are all removed for us automatically, and we can now run our code.
NOTE: In this example, the TypeScript Compiler would have been able to offer us the exact same error even if we hadn’t provided the explicit type annotations
: stringand: number.
TypeScript is very often able to just infer the type of a variable from the way we have used it!
Our source file is our document, TypeScript is our Spell Check
A great analogy for TypeScript’s relationship with our source code, is that of Spell Check’s relationship to a document we are writing in Microsoft Word, for example.
There are three key commonalities between the two examples:
- It can tell us when stuff we have written is objectively, flat-out wrong:
- Spell Check: “we have written a word that does not exist in the dictionary”
- TypeScript: “we have referenced a symbol (e.g. a variable), which is not declared in our program”
- It can suggest that what we have written might be wrong:
- Spell Check: “the tool is not able to fully infer the meaning of a particular clause and suggests rewriting it”
- TypeScript: “the tool is not able to fully infer the type of a particular variable and warns against using it as is”
- Our source can be used for its original purpose, regardless of if there are errors from the tool or not:
- Spell Check: “even if your document has lots of Spell Check errors, you can still print it out and “use” it as document”
- TypeScript: “even if your source code has TypeScript errors, it will still produce JavaScript code which you can execute”
TypeScript is a tool which enables other tools
The TypeScript compiler is made up of a couple of different parts or phases. We are going to finish off this article by looking at how one of those parts - the Parser - offers us the chance to build additional developer tools on top of what TypeScript already does for us.
The result of the “parser step” of the compilation process is what is called an Abstract Syntax Tree, or AST for short.
What is an Abstract Syntax Tree (AST)?
We write our programs in a free text form, as this is a great way for us humans to interact with our computers to get them to do the stuff we want them to. We are not so great at manually composing complex data structures!
However, free text is actually a pretty tricky thing to work with within a compiler in any kind of reasonable way. It may contain things which are unnecessary for the program to function, such as whitespace, or there may be parts which are ambiguous.
For this reason, we ideally want to convert our programs into a data structure which maps out all of the so-called “tokens” we have used, and where they slot into our program.
This data structure is exactly what an AST is!
An AST could be represented in a number of different ways, but let’s take a look at a quick example using our old buddy JSON.
If we have this incredibly basic source code:
var a = 1;The (simplified) output of the TypeScript Compiler’s Parser phase will be the following AST:
{
"pos": 0,
"end": 10,
"kind": 256,
"text": "var a = 1;",
"statements": [
{
"pos": 0,
"end": 10,
"kind": 200,
"declarationList": {
"pos": 0,
"end": 9,
"kind": 219,
"declarations": [
{
"pos": 3,
"end": 9,
"kind": 218,
"name": {
"pos": 3,
"end": 5,
"text": "a"
},
"initializer": {
"pos": 7,
"end": 9,
"kind": 8,
"text": "1"
}
}
]
}
}
]
}The objects in our in our AST are called nodes.
Example: Renaming symbols in VS Code
Internally, the TypeScript Compiler will use the AST it has produced to power a couple of really important things such as the actual Type Checking that occurs when we compile our programs.
But it does not stop there!
We can use the AST to develop our own tooling on top of TypeScript, such as linters, formatters, and analysis tools.
One great example of a tool built on top of this AST generation is the Language Server.
It is beyond the scope of this article to dive into how the Language Server works, but one absolutely killer feature that it enables for us when we write our programs is that of “renaming symbols”.
Let’s say that we have the following source code:
// The name of the author is James
var first_name = 'James';
console.log(first_name);After a thorough code review and appropriate bikeshedding, it is decided that we should switch our variable naming convention to use camel case instead of the snake case we are currently using.
In our code editors, we have long been able to select multiple occurrences of the same text and use multiple cursors to change all of them at once - awesome!
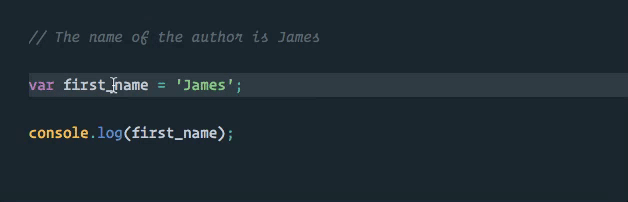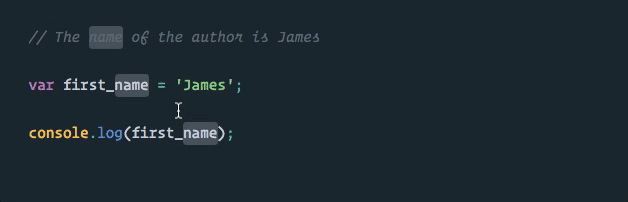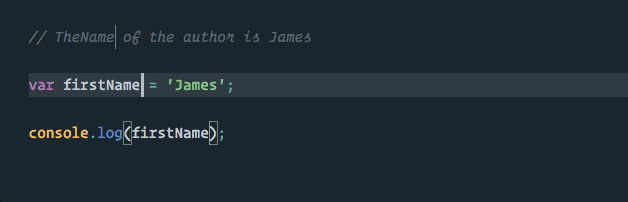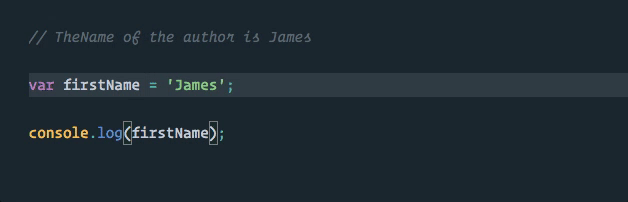
Ah! We have fallen into one of the classic traps that appear when we continue to treat our programs as pieces of text.
The word “name” in our comment, which we did not want to change, got caught up in our manual matching process. We can see how risky such a strategy would be for code changes in a real-world application!
As we learned above, when something like TypeScript generates an AST for our program behind the scenes, it no longer has to interact with our program as if it were free text - each token has its own place in the AST, and its usage is clearly mapped.
We can take advantage of this directly in VS Code using the “rename symbol” option when we right click on our first_name variable (TypeScript Language Server plugins are available for other editors).
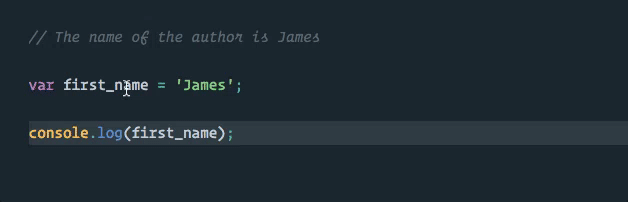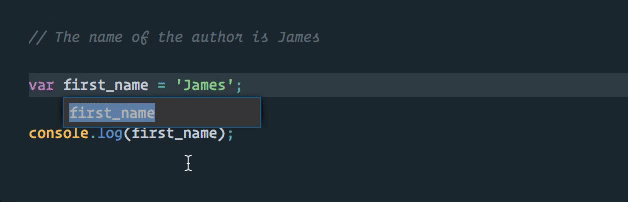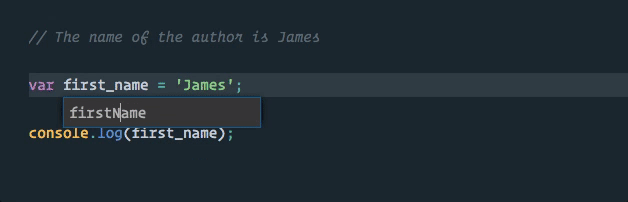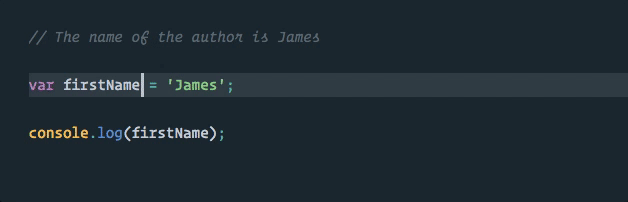
Much better! Now our first_name variable is the only thing that will be changed, and this change will even happen across multiple files in our project if applicable (as with exported and imported values)!
Summary
Phew! We have covered a lot in this post.
We cut through all of the academic distractions to decide on practical definitions for a lot of the terminology that surrounds any discussion on compilers and types.
We looked at compiled vs interpreted languages, run time vs compile time, dynamic vs static typing, and how Abstract Syntax Trees give us a more optimal way to build tooling for our programs.
Importantly, we provided a way of thinking about TypeScript as a tool for our JavaScript development, and how it in turn can be built upon to offer even more amazing utilities, such as renaming symbols as a way of refactoring code.
Onward!